
This is a follow up post to the previous one which showcased the potential of integrating µWheel into DataFusion.
In this post, we introduce an actual integration of the two projects into a Rust crate called datafusion-uwheel, a native DataFusion optimizer which significantly improves query performance for time-based analytics.
This is a joint effort with the DataFusion community. Special thanks to Andrew Lamb for his valuable insights towards this integration.
Post Overview:
- Query Capabilities
- How it Works
- Creating an Optimizer
- Creating an Index
- Preliminary Results
- Next steps
Query Capabilities
Before diving into details about the optimizer, let’s first discuss what kind
of queries can be optimized through datafusion-uwheel.
There are two types of queries that can be enhanced: Temporal Aggregation and Pruning.
Aggregation
SELECT SUM(other_col) FROM my_table
WHERE time_col >= '2022-01-01T00:00:00Z'
AND time_col < '2022-01-01T13:00:00Z'
The following query can be optimized through a sum-based µWheel. Resulting in significant performance improvements over traditional full-scan query execution thanks to pre-computed aggregates across time and µWheel’s query optimizer.
Pruning
µWheel indices can also be used to prune temporal ranges to avoid query execution if its guaranteed there won’t be any matches.
Count Pruning: maintain table count across time to enable count-based pruning.
SELECT * FROM my_table
where time_col >= '2022-01-01T00:00:00Z'
AND time_col < '2022-01-01T13:00:00Z'
MinMax Pruning: maintain min/max values for a column across time.
SELECT * FROM my_table
WHERE time_col >= '2022-01-01T00:00:00Z'
AND time_col < '2022-01-01T13:00:00Z'
AND other_col > 100
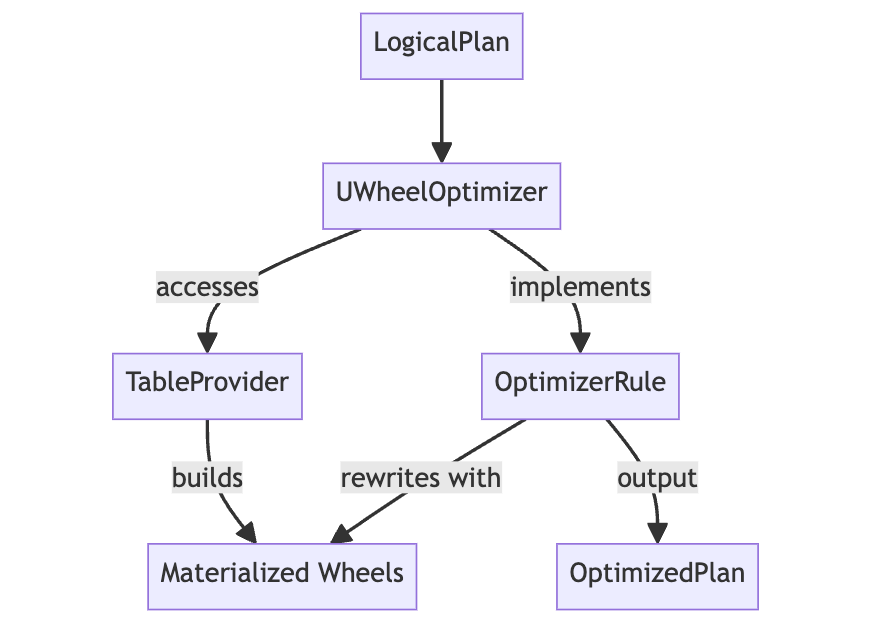
How it works
The optimizer leverages µWheel indices to rewrite DataFusion plans at the logical level, either providing plan-time aggregates or skipping execution based on pruning.
The following diagram shows at a high-level how the optimizer works.
Whereas this code snippet illustrates the rewrite process at the code level:
fn rewrite(
&self,
plan: LogicalPlan,
_config: &dyn OptimizerConfig,
) -> Result<Transformed<LogicalPlan>> {
// Attemps to rewrite a logical plan to a uwheel-based plan that either provides
// plan-time aggregates or skips execution based on min/max pruning.
if let Some(rewritten) = self.try_rewrite(&plan) {
Ok(Transformed::yes(rewritten))
} else {
Ok(Transformed::no(plan))
}
}
Internally, the rewriter looks for temporal patterns and aggregation functions
that match the stored wheel indices. If there is a match then the target wheel is
queried and the aggregate result gets stored within a
MemTable
and is returned as a LogicalPlan::TableScan.
For instance, assuming a single-value aggregate result, the following function illustrates the transformation into a new optimized logical plan.
// Converts a uwheel aggregate result to a TableScan with a MemTable as source
fn agg_to_table_scan(result: f64, schema: SchemaRef) -> Result<LogicalPlan> {
let data = Float64Array::from(vec![result]);
let record_batch = RecordBatch::try_new(schema.clone(), vec![Arc::new(data)])?;
let df_schema = Arc::new(DFSchema::try_from(schema.clone())?);
let mem_table = MemTable::try_new(schema, vec![vec![record_batch]])?;
mem_table_as_table_scan(mem_table, df_schema)
}
Creating an Optimizer
A UWheelOptimizer is created through a Builder struct
that takes the following parameters:
- DataFusion TableProvider (required)
- Time column (required)
- Table name (required)
- Time Range (optional)
- MinMax columns (optional)
The following code shows an example using the NYC Taxi dataset.
// Builds a UWheelOptimizer using a Parquet TableProvider
let optimizer: Arc<UWheelOptimizer> = Arc::new(
Builder::new("tpep_dropoff_datetime")
.with_name("yellow_tripdata")
.with_min_max_wheels(vec!["fare_amount"])
.with_time_range(
ScalarValue::Utf8(Some("2022-01-01T00:00:00Z".to_string())),
ScalarValue::Utf8(Some("2022-02-01T00:00:00Z".to_string())),
)?
.build_with_provider(provider)
.await?
);
Now this optimizer can be configured as a custom OptimizerRule in DataFusion.
Creating an Index
We now show how custom µWheel indices can be built using the IndexBuilder struct.
It requires two mandatory parameters, a column name and an aggregate type.
It is also possible to configure which time range the index should cover,
and whether the index should include any extra predicates.
Assuming we would want to index the sum of fare amounts across time for the NYC Taxi dataset, to support queries like this one:
SELECT SUM(fare_amount) FROM yellow_tripdata
WHERE tpep_dropoff_datetime >= '{}'
AND tpep_dropoff_datetime < '{}'
We would then create the index through the API:
optimizer
.build_index(
IndexBuilder::with_col_and_aggregate(
"fare_amount",
AggregateType::Sum,
)
.with_time_range(
ScalarValue::Utf8(Some("2022-01-01T00:00:00Z".to_string())),
ScalarValue::Utf8(Some("2022-02-01T00:00:00Z".to_string())),
)?,
)
.await?;
It is also possible to build indices for custom DataFusion expressions
using the with_filter method. Let’s say that we also want to include a
predicate on passenger count where we are only interested in trips with 3 passengers.
SELECT SUM(fare_amount) FROM yellow_tripdata
WHERE tpep_dropoff_datetime >= '{}'
AND tpep_dropoff_datetime < '{}'
AND passenger_count = 3
This index can be built through the following code.
optimizer
.build_index(
IndexBuilder::with_col_and_aggregate(
"fare_amount",
AggregateType::Sum,
)
.with_filter(col("passenger_count").eq(lit(3.0)))
.with_time_range(
ScalarValue::Utf8(Some("2022-01-01T00:00:00Z".to_string())),
ScalarValue::Utf8(Some("2022-02-01T00:00:00Z".to_string())),
)?,
)
.await?;
Preliminary Results
Similarly to the previous post, we compare the performance of the optimizer
against regular DataFusion using the NYC Taxi dataset (Parquet) across
the dates 2022-01-01 and 2022-02-01. We use tpep_dropoff_datetime as
our time column and for each query time ranges are generated
at different granularities (e.g., seconds, minutes).
COUNT(*) Aggregation
SELECT COUNT(*) FROM yellow_tripdata
WHERE tpep_dropoff_datetime >= '{}'
AND tpep_dropoff_datetime < '{}'
| System | p50 | p99 | p99.9 |
|---|---|---|---|
| datafusion (Second Ranges) | 49529µs | 53889µs | 58729µs |
| datafusion (Minute Ranges) | 49623µs | 50751µs | 51799µs |
| datafusion-uwheel (Second Ranges) | 59µs | 99µs | 263µs |
| datafusion-uwheel (Minute Ranges) | 54µs | 92µs | 208µs |
Index size usage: 20.8 MiB
SUM Aggregation with Predicate
SELECT SUM(fare_amount) FROM yellow_tripdata
WHERE tpep_dropoff_datetime >= '{}'
AND tpep_dropoff_datetime < '{}'
AND passenger_count = 3
| System | p50 | p99 | p99.9 |
|---|---|---|---|
| datafusion (Second Ranges) | 72447µs | 76971µs | 80787µs |
| datafusion (Minute Ranges) | 72355µs | 73319µs | 76159µs |
| datafusion-uwheel (Second Ranges) | 62µs | 74µs | 256µs |
| datafusion-uwheel (Minute Ranges) | 65µs | 84µs | 165µs |
Index size usage: 41.6 MiB
MinMax Pruning
SELECT * FROM yellow_tripdata
WHERE tpep_dropoff_datetime >= '{}'
AND tpep_dropoff_datetime < '{}'
AND fare_amount > '{}' # Random amount from 1 to 1000.0
| System | p50 | p99 | p99.9 |
|---|---|---|---|
| datafusion (Second Ranges) | 242103µs | 246999µs | 251527µs |
| datafusion (Minute Ranges) | 242151µs | 246935µs | 255415µs |
| datafusion-uwheel (Second Ranges) | 1272µs | 247511µs | 249471µs |
| datafusion-uwheel (Minute Ranges) | 1258µs | 248783µs | 253695µs |
As seen by the p50 latency, the optimizer is able to skip query processing on certain temporal ranges and fare amounts through the use of a MinMax wheel index.
Index size usage: 41.6 MiB
Next steps
datafusion-uwheel is still in early development stages and not yet production ready.
Near-term plans include:
- Support more types of aggregations and expressions.
- Add more examples, tests, and documentation.
- Run more extensive benchmarks
Long-term plans include:
- Support streaming incremental maintenance of wheel indices.
- Storage support for making wheel indices persistent.
- Build and maintain indices in a smart way based on query patterns.